Paralelismo
Playlists
- Desta aula: https://www.youtube.com/playlist?list=PLYItvall0TqJ1jteUbGOHfBycg5NM9thq
- Do curso: https://www.youtube.com/playlist?list=PLYItvall0TqJ25sVTLcMhxsE0Hci58mpQ
Estas notas de aula são baseadas no livro “Parallel and Concurrent Programming in Haskell”, por Simon Marlow: https://simonmar.github.io/pages/pcph.html
1 Eval Monad
A biblioteca Control.Parallel.Strategies fornece os seguintes tipos e
funções para criar paralelismo:
data Eval a = ...
instance Monad Eval where ...
runEval :: Eval a -> a
rpar :: a -> Eval a
rseq :: a -> Eval a
-
A função
rparindica que meu argumento pode ser executado em paralelo. -
A função
rseqdiz meu argumento deve ser avaliado e o programa deve esperar pelo resultado. -
Em ambos os casos a avaliação é para WHNF . Além disso, o argumento de
rpardeve ser uma expressão ainda não avaliada, ou nada útil será feito. -
Finalmente, a função
runEvalexecuta uma expressão (em paralelo ou não) e retorna o resultado dessa computação. -
Note que a Monad Eval é pura e pode ser utilizada fora de funções com
IO.
Para poder utilizar a Monad `Eval` e os exemplos desta página siga o seguintes passos:
Crie um projeto usando o Stack:
stack new paralelo simple
stack setup
-
Edite o arquivo
paralelo.cabale na linhabuild-dependsacrescente as bibliotecasparallel, time. -
Na linha anterior a
hs-source-dirsacrescente a linhaghc-options: -threaded -rtsopts -with-rtsopts=-N -eventlog
No arquivo Main.hs acrescente:
import Control.Parallel.Strategies
import Control.Exception
import Data.Time.Clock
Vamos começar com um exemplo simples. Considere a implementação ingênua de Fibonacci:
fib :: Integer -> Integer
fib 0 = 0
fib 1 = 1
fib n = fib (n - 1) + fib (n - 2)
Digamos que queremos obter o resultado de fib 41 e fib 40:
f = (fib 41, fib 40)
Podemos executar as duas chamadas de fib em paralelo!
fparpar :: Eval (Integer, Integer)
fparpar = do a <- rpar (fib 41)
b <- rpar (fib 40)
return (a, b)
Altere a função main para:
main :: IO ()
main = do
t0 <- getCurrentTime
-- evaluate força avaliação para WHNF
r <- evaluate (runEval fparpar)
t1 <- getCurrentTime
print (diffUTCTime t1 t0)
print r -- vamos esperar o resultado terminar
t2 <- getCurrentTime
print (diffUTCTime t2 t0)
Compile com stack build --profile e execute com:
$ stack exec paralelo --RTS -- +RTS -N1
Explicando os parâmetros:
-threaded: compile com suporte a multithreading-eventlog: permite criar um log do uso de threads-rtsopts: embute opções no seu programa+RTS: flag para indicar opções embutidas-Nx: quantas threads usar-s: estatísticas de execução-ls: gera log para o threadscope
Para o parâmetro N1 a saída da execução retornará:
0.000002s
(165580141,102334155)
15.691738s
Para o parâmetro N2 a saída da execução retornará:
0.000002s
(165580141,102334155)
9.996815s
- Com duas threads o tempo é reduzido pois cada thread calculou um valor de Fibonacci em paralelo.
- Note que o tempo não se reduziu pela metade pois as tarefas são desproporcionais. ( Você sabe explicar porquê? )
1.1 rpar-rpar
- A estratégia
rpar-rparnão aguarda o final da computação para liberar a execução de outras tarefas:
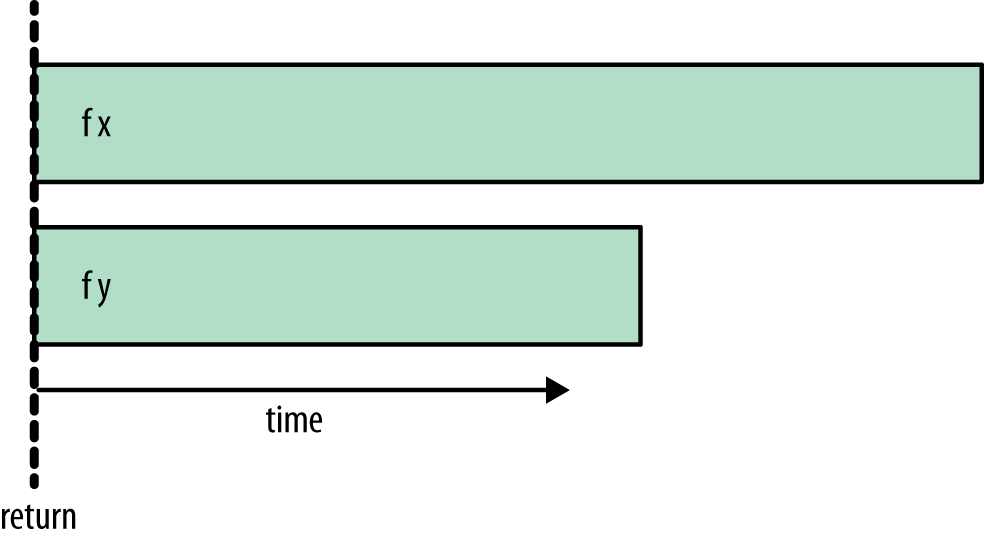
Figure 1: rpar-rpar
1.2 rpar-rseq
- Definindo a expressão
fparseqe alterando a funçãomainpara utilizá-la:
fparseq :: Eval (Integer, Integer)
fparseq = do a <- rpar (fib 41)
b <- rseq (fib 40)
return (a,b)
- Temos como resultado para
N2:
5.979055s
(165580141,102334155)
9.834702s
Agora runEval aguarda a finalização do processamento de b antes
de liberar para outros processos.
A estratégia rpar-rseq aguarda a finalização do processamento seq:
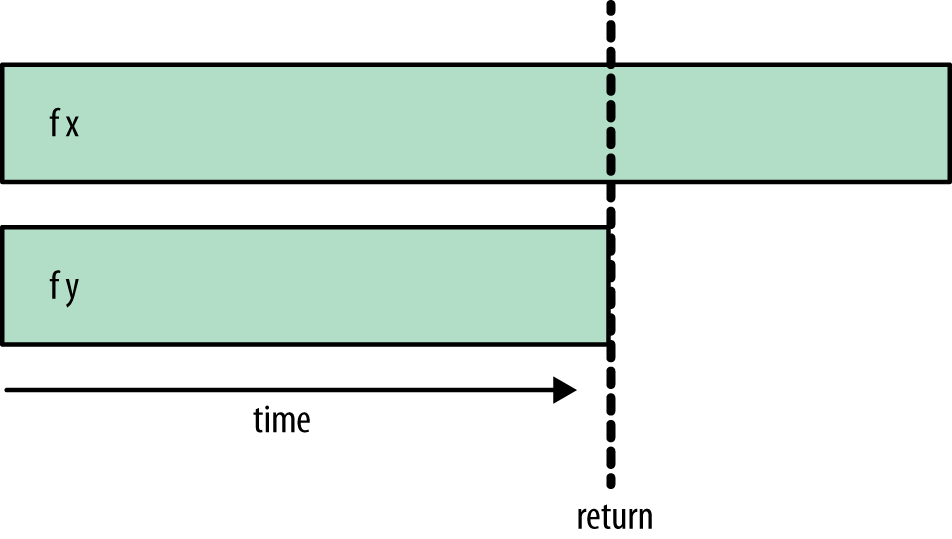
Figure 2: rpar-rseq
1.3 rpar-rpar-rseq-rseq
Finalmente podemos fazer:
fparparseq :: Eval (Integer, Integer)
fparparseq = do a <- rpar (fib 41)
b <- rpar (fib 40)
rseq a
rseq b
return (a,b)
E o resultado da execução com N2 é:
(165580141,102334155)
10.094287s
- Agora
runEvalaguarda o resultado de todos os threads antes de retornar:
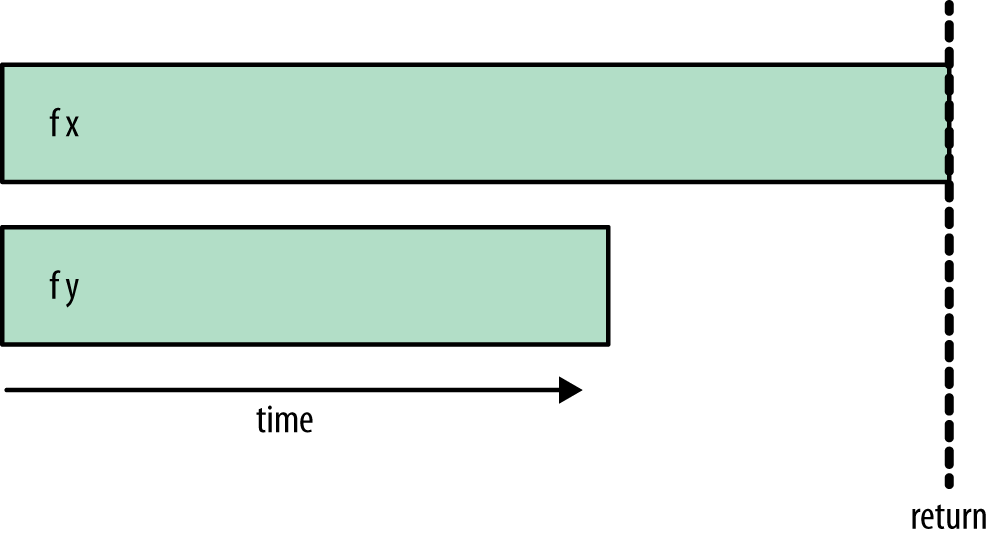
Figure 3: rpar-rpar-rseq-rseq
Escolhendo a estratégia
-
A escolha da combinação de estratégias depende muito do algoritmo que está sendo implementado.
-
Se pretendemos gerar mais paralelismo e não dependemos dos resultados anteriores,
rpar-rparfaz sentido como estratégia. -
Porém, se já geramos todo o paralelismo desejado e precisamos aguardar o resultado
rpar-rpar-rseq-rseqpode ser a melhor estratégia.
2 Estratégias de Avaliação
A biblioteca Control.Parallel.Strategies define também o tipo:
type Strategies a = a -> Eval a
- A ideia desse tipo é permitir a abstração de estratégias de paralelismo para tipos de dados, seguindo o exemplo anterior, poderíamos definir:
-- :: (a,b) -> Eval (a,b)
parPair :: Strategy (a,b)
parPair (a,b) = do a' <- rpar a
b' <- rpar b
return (a',b')
Dessa forma podemos escrever:
runEval (parPair (fib 41, fib 40))
Mas seria bom separar a parte sequencial da parte paralela para uma melhor manutenção do código.
Podemos então definir:
using :: a -> Strategy a -> a
x `using` s = runEval (s x)
Com isso nosso código se torna:
(fib 41, fib 40) `using` parPair
- Dessa forma, uma vez que meu programa sequencial está feito, podemos adicionar paralelismo sem me preocupar em quebrar o programa!
Estratégias parametrizadas
- A nossa função
parPairainda é restritiva em relação a estratégia adotada.- Precisamos criar outras funções similares para adotar outras estratégias.
Uma generalização pode ser escrita como:
evalPair :: Strategy a -> Strategy b -> Strategy (a,b)
evalPair sa sb (a,b) = do a' <- sa a
b' <- sb b
return (a',b')
Nossa função parPair pode ser reescrita como:
parPair :: Strategy (a,b)
parPair = evalPair rpar rpar
- Ainda temos uma restrição, pois ou utilizamos
rparourseq. - Além disso ambas avaliam a expressão para a WHNF. Para resolver esses problemas podemos utilizar as funções:
rdeepseq :: NFData a => Strategy a
rdeepseq x = rseq (force x)
rparWith :: Strategy a -> Strategy a
rparWith strat = parEval . strat
Dessa forma podemos fazer:
parPair :: Strategy a -> Strategy b -> Strategy (a,b)
parPair sa sb = evalPair (rparWith sa) (rparWith sb)
E podemos garantir uma estratégia paralela que avalia a estrutura por completo:
(fib 41, fib 40) `using` parPair rdeepseq rdeepseq
2.1 Estratégia para listas
Como as listas representam uma estrutura importante no Haskell, a
biblioteca já vem com a estratégia parList de tal forma que podemos
fazer:
map f xs `using` parList rseq
Essa é justamente a definição de parMap:
parMap :: (a -> b) -> [a] -> [b]
parMap f xs = map f xs `using` parList rseq
3 Threadscope
Vamos definir a seguinte função que calcula a média dos valores de cada linha de uma matriz:
mean :: [[Double]] -> [Double]
mean xss = map mean' xss `using` parList rseq
where
mean' xs = sum xs / fromIntegral (length xs)
Cada elemento de xss vai ser potencialmente avaliado em paralelo.
Compilando e executando esse código com o parâmetro -s obtemos:
Total time 1.381s ( 1.255s elapsed)
O primeiro valor é a soma do tempo de máquina de cada thread, o segundo valor é o tempo total real de execução do programa.
O que houve?
3.1 Threadscope
Para instalar o programa threadscope faça o download em http://hackage.haskell.org/package/threadscope e:
$ tar zxvf threadscope-0.2.13.tar.gz
$ cd threadscope-0.2.13
$ stack install threadscope
Execute o programa da média incluindo o parâmetro -ls e em seguida:
$ threadscope media.eventlog
Os gráficos em verde mostram o trabalho feito por cada core do computador:
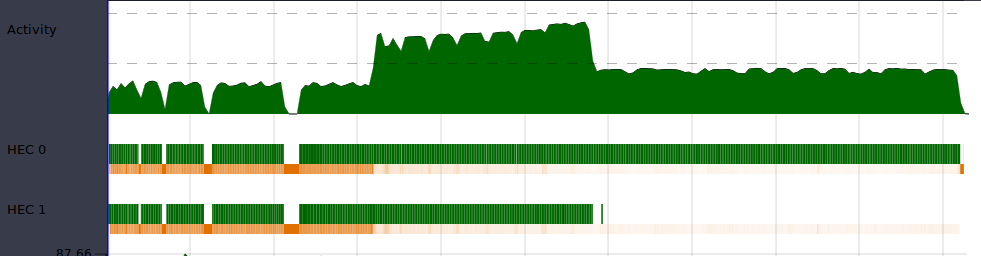
Por que um core fez o dobro do trabalho?
3.2 Sparks
- No Haskell o paralelismo é feito através da criação de sparks
- Um spark é uma promessa de algo a ser computado e que pode ser (mas não necessariamente será) computado em paralelo.
- Cada elemento da lista gera um spark, esses sparks são inseridos em um pool que alimenta os processos paralelos.
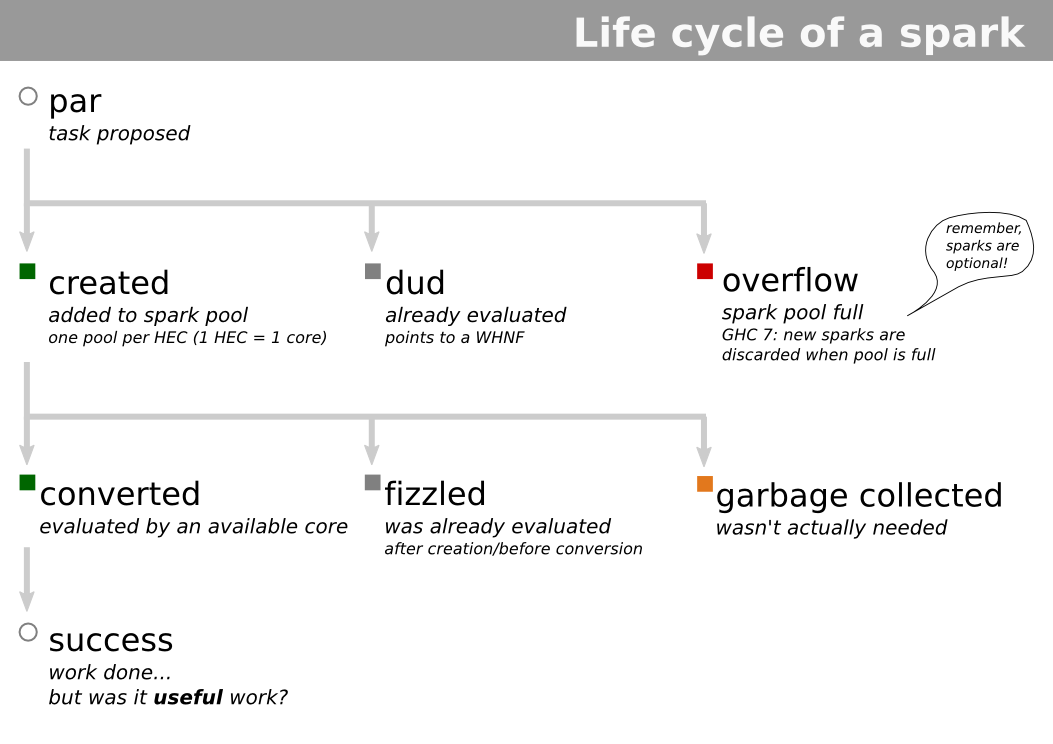
- Cada elemento que é passado para a função
rparcria um spark e que é inserido no pool.
- Quando um processo pega esse spark do pool, ele é convertido em um processo e então é executado.
- No momento da criação, antes de criar o spark, é verificado se a expressão não foi avaliada anteriormente. Caso tenha sido, ela vira um dud e aponta para essa avaliação prévia.
- Se o pool estiver cheio no momento, ela retorna o status overflow e não cria o spark, simplesmente avalia a expressão no processo principal.
- Se no momento de ser retirado do pool ele já tiver sido avaliado em outro momento, o spark retorna status fizzled, similar ao dud.
- Finalmente, se essa expressão nunca for requisitada, então ela é desalocada da memória pelo garbage collector.
Sinais de problemas:
-
Poucos sparks → pode ser paralelizado ainda mais
-
Muitos sparks → paralelizando demais
-
Muitos duds e fizzles → estratégia não otimizada.
Voltando ao nosso exemplo, se olharmos para a criação de sparks, percebemos que ocorreu overflow (parte vermelha), ou seja, criamos muitos sparks em um tempo muito curto:
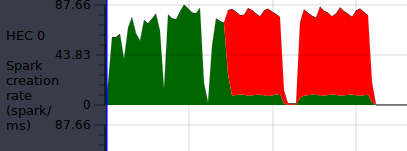
Vamos tirar a estratégia…
mean :: [[Double]] -> [Double]
mean xss = map mean' xss
where
mean' xs = (sum xs) / (fromIntegral $ length xs)
E criar uma nova função que aplica a função mean sequencial em
pedaços de nossa matriz:
meanPar :: [[Double]] -> [Double]
meanPar xss = concat medias
where
medias = map mean chunks `using` parList rseq
chunks = chunksOf 1000 xss
Agora criaremos menos sparks, pois cada spark vai cuidar de 1000
elementos de xss.
O resultado:
Total time 1.289s ( 1.215s elapsed)
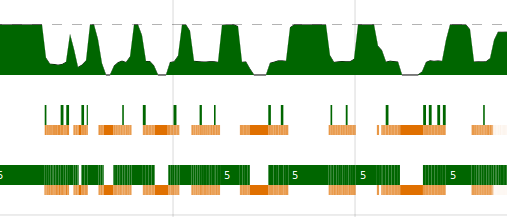
Não tem mais overflow! Mas…
A função mean é aplicada em paralelo até encontrar a WHNF, ou seja,
apenas a promessa de calcular a média de cada linha!
Vamos usar a estratégia rdeepseq.
meanPar :: [[Double]] -> [Double]
meanPar xss = concat medias
where
medias = map mean chunks `using` parList rdeepseq
chunks = chunksOf 1000 xss
Total time 1.303s ( 0.749s elapsed)
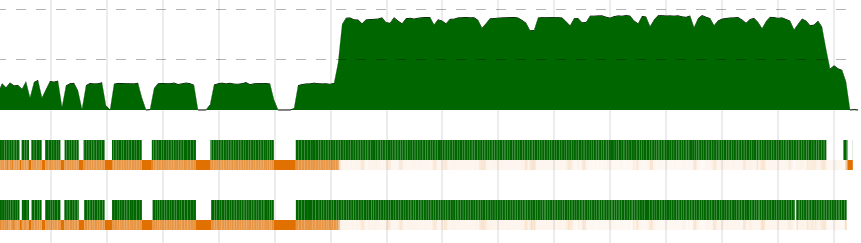
😊
4 Disclaimer
Estes slides foram preparados para os cursos de Paradigmas de Programação e Desenvolvimento Orientado a Tipos na UFABC.
Este material pode ser usado livremente desde que sejam mantidos, além deste aviso, os créditos aos autores e instituições.
