Monads
Playlists
- Desta aula:
- Do curso: https://www.youtube.com/playlist?list=PLYItvall0TqJ25sVTLcMhxsE0Hci58mpQ
1 Monads
Vamos começar definindo um tipo de dado que representa expressões matemáticas:
data Expr = Val Int
| Add Expr Expr
| Sub Expr Expr
| Mul Expr Expr
| Div Expr Expr
Se quisermos avaliar (calcular) essa expressão podemos definir:
eval :: Expr -> Int
eval (Val n) = n
eval (Add x y) = (eval x) + (eval y)
eval (Sub x y) = (eval x) - (eval y)
eval (Mul x y) = (eval x) * (eval y)
eval (Div x y) = (eval x) `div` (eval y)
Porém, essa função é parcial, ou seja, não é definida para todos os possíveis valores de entrada dados pelo seu tipo. Por exemplo, se fizermos:
> eval (Div (Val 1) (Val 0))
*** Exception: divide by zero
E exceções (atrasadas) em um contexto onde a sua linguagem de programação é preguiçosa podem causar todo tipo de confusão. Por exemplo: Porque estou tomando um erro de divisão por zero quando estou somando dois inteiros?.
1.1 Maybe
Queremos sempre que possível criar funções totais. Podemos resolver
este caso usando maybeDiv e Maybe. Para este exemplo, vamos
focar apenas na divisão:
eval :: Expr -> Maybe Int
eval (Val n) = Just n
eval (Div x y) = case eval x of
Nothing -> Nothing
Just n -> case eval y of
Nothing -> Nothing
Just m -> maybeDiv n m
Se repetirmos o exemplo anterior, agora obtemos:
> eval (Div (Val 1) (Val 0))
Nothing
Mas o código ficou confuso. O encadeamento de cases pode logo sair do controle.
Para melhorar este exemplo, podemos lançar mão do uso do
Applicative. O Applicative pode resolver muitos problemas de
encadeamento de funções com efeito.
Estamos interessados em escrever algo como o seguinte:
pure maybeDiv <*> eval x <*> eval y
Mas maybeDiv tem tipo Int -> Int -> Maybe Int e deveria ser
Int -> Int -> Int para o uso de applicativo.
O problema aqui é que o uso de Applicative é para sequências de computações que podem ter efeitos mas que são independentes entre si.
O que desejamos, na verdade, é uma sequência de computações com
efeito mas que uma computação dependa da anterior. Em outras
palavras, precisamos de uma função que capture nosso padrão de
case of:
vincular :: Maybe a -> (a -> Maybe b) -> Maybe b
vincular mx g = case mx of
Nothing -> Nothing
Just x -> g x
O nome vincular indica que estamos vinculando o resultado da
computação de mx ao argumento da função g.
Em Haskell esse operador é conhecido como bind e definido como:
(>>=) :: Maybe a -> (a -> Maybe b) -> Maybe b
Qualquer semelhança com o logo de Haskell, é mera coincidência 😄
Em teoria das categorias um Monad pode ser visto como um Monoid das categorias dos Functors.
- O elemento identidade é o
return - O operador associativo é uma variação de
(>>=)com a assinatura:(>=>) ::Monad m=> (a -> m b) -> (b -> m c) -> (a -> m c)
Ou seja, duas funções que transformam um valor puro em um Monad podem ser combinadas formando uma terceira função.
O operador (>=>) é também chamado de operador peixe ( fish operator ).
Agora já podemos reescrever a função eval como:
eval :: Expr -> Maybe Int
eval (Val n) = Just n
eval (Div x y) = eval x >>= \n ->
eval y >>= \m ->
maybeDiv n m
E se a executarmos passo a passo, podemos ver como ela se comporta:
> eval (Div (Val (Just 4)) (Val (Just 2)))
=> (Just 4) >>= \n ->
(Just 2) >>= \m -> maybeDiv n m
=> (Just 2) >>= \m -> maybeDiv 4 m
=> maybeDiv 4 2
E no caso de termos um Nothing à esquerda ficaria:
> eval (Div (Val (Nothing)) (Val (Just 2)))
=> Nothing >>= \n ->
(Just 2) >>= \m -> maybeDiv n m
=> Nothing
Já no caso de termos um Nothing à direita, temos:
> eval (Div (Val (Just 4)) (Val (Nothing))
=> (Just 4) >>= \n ->
Nothing >>= \m -> maybeDiv n m
=> Nothing >>= \m -> maybeDiv 4 m
=> Nothing
Podemos generalizar uma expressão construída com o operador (>>=)
utilizando a seguinte estrutura:
m1 >>= \x1 ->
m2 >>= \x2 ->
...
mn >>= \xn ->
f x1 x2 ... xn
Esta estrutura indica um encadeamento de computação sequencial para
chegar a uma aplicação de função. O operador bind (>>=) garante
que se uma computação falhar, ela pára imediatamente e reporta a falha
(em forma de Nothing, [], etc.)
1.2 Monads: Syntactic Sugar
A generalização do uso do bind mostrada acima é tão comum que a linguagem dispõe de um açúcar sintático só para ela! Podemos reescrever a expressão com a notação chamada do-notation :
do x1 <- m1
x2 <- m2
...
xn <- mn
f x1 x2 ... xn
Utilizando esse açúcar, podemos reescrever eval novamente como:
eval :: Expr -> Maybe Int
eval (Val n) = Just n
eval (Div x y) = do n <- eval x
m <- eval y
safeDiv n m
Que captura uma sequência de computações que devem respeitar a ordem, são dependentes e podem falhar. Uma notação imperativa? 🤔
Esse tipo de operação forma uma nova classe de tipos denominada Monad :
class Applicative m => Monad m where
return :: a -> m a
(>>=) :: m a -> (a -> m b) -> m b
return = pure
Note que para ser uma Monad, um tipo precisa anteriormente ser um
Applicative.
Uma Monad tem, além do operador bind (>>=), uma função
chamada return que é apenas um sinônimo para a função pure já
definina na instância de Applicative do tipo em questão.
Antigamente (GHC < 7.10) não era necessário fazer com que um tipo
fosse parte da classe de tipos Applicative para que fosse
incluído na classe de tipos Monad. Isto mudou com a proposta
AMP
(Applicative-Monad Proposal) a partir da qual passou-se, entre
outras coisas, a considerar a Monad como sendo uma subclasse de
Applicative.
Como já existia a função return em Monad, decidiu-se (para
evitar quebra-quebra de código) definir automaticamente a
implementação de return = pure. Essa implementação garantiria que
códigos antigos continuassem a funcionar sem alterações (a menos da
criação de uma instância de Applicative) contanto que ele utilizasse
implementações legais de Applicative e Monad.
Nós já tínhamos escrito a definição de Monad Maybe mas podemos deixá-la
mais clara utilizando Pattern Matching:
instance Monad Maybe where
Nothing >>= _ = Nothing
(Just x) >>= f = f x
1.3 SafeNum encontra uma Monad para chamar de sua
O SafeNum agora pode ser escrito utilizando Monad.
-- Versão diet
f3' :: Int -> Int -> SafeNum Int
f3' x y =
safeDiv x y >>= \xy ->
safeDiv y x >>= \yx ->
safeAdd xy yx
-- Versão açúcarada
f3 :: Int -> Int -> SafeNum Int
f3 x y = do
xy <- safeDiv x y
yx <- safeDiv y x
safeAdd xy yx
Quando colocado lado-a-lado à versões anteriores, fica clara a vantagem da abordagem baseada em mônadas:
-- Versão "pura"
f0 :: Int -> Int -> SafeNum Int
f0 x y
| isSafe xy && isSafe yx = safeAdd (unbox xy) (unbox yx)
| (not.isSafe) xy = xy
| otherwise = yx
where
xy = safeDiv x y
yx = safeDiv y x
unbox (SafeNum x) = x
isSafe (SafeNum _) = True
isSafe _ = False
-- Versão com functors
f1 :: Int -> Int -> SafeNum Int
f1 x y =
let xy = safeDiv x y
yx = safeDiv y x
safeAddXY = fmap safeAdd xy
safeXYPlusYX = fmap (`fmap` yx) safeAddXY
in
(flatten.flatten) safeXYPlusYX
-- Versão com applicative
f2 :: Int -> Int -> SafeNum Int
f2 x y =
let xy = safeDiv x y
yx = safeDiv y x
in
flatten $ pure safeAdd <*> xy <*> yx
-- Versão com monad
f3 :: Int -> Int -> SafeNum Int
f3 x y = do
xy <- safeDiv x y
yx <- safeDiv y x
safeAdd xy yx
1.4 Exercício 1
Escreva a instância de Monad para o tipo SafeNum.
data SafeNum a = NaN | NegInf| PosInf | SafeNum a deriving Show
2 Functor, Applicative, Monad: Resumão
A princípio pode ficar confusa a diferença entre as classes
Functor, Applicative e Monad. Por isto colocamos abaixo um
rápido resumo do que vimos até agora.
Um valor é puro quando ele não está envolto em um contexto. Consequentemente um valor é considerado impuro quando ele está contido em um contexto. Exemplos:
| Puro | Impuro | Contexto |
|---|---|---|
3 |
Just 3 |
Maybe Int |
3 |
Right 3 |
Either String Int |
3 |
[3] |
[Int] |
"Olá" |
Right "Olá" |
Either String String |
2.78 |
[2.78] |
[Float] |
| - | Nothing |
Maybe Int Como, por exemplo, representando o resultado de uma divisão por 0. |
Uma analogia (que funciona apenas até certo ponto) é pensar no contexto como sendo uma caixa que contém (ou pode conter) o valor (ou valores) de interesse. (Cuidado para não esticar demais essa analogia pois ela logo pode estourar!).
Em resumo temos:
Functor-fmap, ou na versão infixa,(<$>), permite que apliquemos uma função com entrada e saída puras (a -> b) a um valor impuro (f a). O valor calculado é devolvido no mesmo contexto (f) que contém o valor de entrada (f b).fmap :: Functor f => (a -> b) -> f a -> f b > fmap even (Just 4) Just TrueApplicative-(<*>)(lê-se apply), permite que apliquemos uma função com entrada e saida puras contida em um contexto (f (a -> b)) a um valor impuro (f a). Assim como o functor, o valor calculado é devolvido no mesmo contexto (f) que contém a função e o valor de entrada (f b).O uso de applicatives, contudo, passa a ser bem mais útil quando consideramos funções com dois um mais argumentos para os quais o uso de functores passa a ser inconveniente:(<*>) :: Applicative f => f (a -> b) -> f a -> f b > Just even <*> Just 4 Just True> pure (+) <*> safeDiv 4 5 <*> safeDiv 10 2 Just 5 -- Uma versão mais comum é usar o fmap infixo na primeira aplicação > (+) <$> safeDiv 4 5 <*> safeDiv 10 2 Just 5Monad-(>>=)(lê-se bind), permite que apliquemos uma função com entrada pura e saída impura (a -> m b) em um valor impuro (m a). O valor calculado é devolvido no mesmo contexto (m) que contém o valor e que é devolvido pela função aplicada (m b).A real vantagem do emprego de mônadas, contudo, aparece quando há uma dependência entre as computações:(>>=) :: Monad m => m a -> (a -> m b) -> m b > Just 4 >>= \x -> return (even x) Just True -- ou usando a versão com açúcar > do > x <- Just 4 > return (even x) > safeDiv 4 5 >>= \x-> safeDiv 10 2 >>= \y -> return (x + y) Just 5 -- ou usando a versão com açúcar > do > x <- safeDiv 4 5 > y <- safeDiv 10 2 > return (x + y) Just 5do x <- safeDiv 4 5 -- note o uso de x no cálculo de y y <- safeDiv 10 x return (x + y)
TL;DR
| Classe | Operador | Exemplo |
|---|---|---|
| - | ($), espaço |
even $ 5, even 5 |
| Functor | fmap, (<$>) |
fmap even (Just 5), even <$> Just 5 |
| Applicative | (<*>) |
pure even <*> Just 5, (+) <$> safeDiv 4 5 <*> safeDiv 10 2 |
| Monad | (>>=) |
Just 5 >>= \x -> return (even x), safeDiv 4 5 >>= \x-> safeDiv 10 2 >>= \y -> return (x + y) |

3 Monads e Efeitos
Embora a linguagem Haskell seja conhecida como uma linguagem puramente funcional . Existe um limite do quanto nosso programa pode ser puro!
Imagine um programa que computa 1 milhão de casas decimais de \(\pi\) só que não imprime o resultado por causa da ausência de efeitos colaterais.
As funções impuras são necessárias para diversas ocasiões conforme apontado por Eugenio Moggi:
- Parcialidade
- Não-determinismo
- Exceções
- Efeitos colaterais: Read only, Write only, Read/Write
- Continuações
- Entrada e Saída Interativa
3.1 Parcialidade
Já demos um spoiler sobre como funções parciais podem ser
transformadas em totais na seção que falamos sobre a mônada Maybe.
O uso de Maybe é muito prático quando temos uma função que pode
não terminar ou que seja ⊥ (bottom):
f :: a -> Bool
retorna True, False ou ⊥.
3.2 Não-determinismo
Quando uma função pode retornar diferentes saídas dependendo de certas condições internas ou externas, ela é dita não-determinística .
Por exemplo, ao jogar um dado, podemos ter seis saídas diferentes!
Uma forma de modelar não-determinismo é com uso de listas:
data Dado = Um | Dois | Tres | Quatro | Cinco | Seis
deriving (Show, Bounded, Enum, Eq)
jogaDado = [Um .. Seis]
A cada jogada de dados, eu recebo um novo número de Um a Seis.
Quais combinações eu posso ter ao jogar os dados duas vezes?
jogaDuasVezes = do
dado1 <- jogaDado
dado2 <- jogaDado
return (dado1, dado2)
jogaDuasVezes
Saída:
Imagine agora que esse dado é mágico, e toda vez que ele cai em um número par, o próximo é ímpar e vice-versa:
magica :: Dado -> [Dado]
magica dado
| any (dado==) [Um, Tres, Cinco] = [Dois, Quatro, Seis]
| otherwise = [Um, Tres, Cinco]
jogaDuasVezes' :: [(Dado, Dado)]
jogaDuasVezes' = do
dado1 <- jogaDado
dado2 <- magica dado1
return (dado1, dado2)
jogaDuasVezes'
Saída:
- A Monad lista é definida como:
instance Monad [] where
xs >>= f = [y | x <- xs, y <- f x]
Nossa função jogaDuasVezes usando bind fica:
jogaDuasVezes :: [(Dado, Dado)]
jogaDuasVezes = jogaDado >>= \dado1 ->
jogaDado >>= \dado2 ->
return (dado1, dado2)
E a versão jogaDuasVezes' como:
jogaDuasVezes' :: [(Dado, Dado)]
jogaDuasVezes' = jogaDado >>= \dado1 ->
magica dado1 >>= \dado2 ->
return (dado1, dado2)
- Para gerar todas as combinações de elementos de duas listas pode ser escrito como:
pares :: [a] -> [b] -> [(a,b)]
pares xs ys = xs >>= \x ->
ys >>= \y ->
return (x,y) -- [(x,y)]
- Ou em do-notation:
pares :: [a] -> [b] -> [(a,b)]
pares xs ys = do x <- xs
y <- ys
return (x,y)
> pares [1,2] [3,4]
=> [1,2] >>= \x ->
[3,4] >>= \y ->
[(x,y)]
=> [x' | x <- [1,2],
x' <- \x -> [3,4] >>= \y -> [(x,y)]]
=> [x' | x <- [1,2],
x' <- \x -> [y' | y <- [3,4], y' <- [(x,y)]]
=> [x' | x <- [1,2],
x' <- \x -> [y' | y' <- [(x,3), (x,4)]]
=> [x' | x <- [1,2],
x' <- \x -> [(x,3), (x,4)]]
=> [x' | x' <- [(1,3),(1,4),(2,3),(2,4)]]
=> [(1,3),(1,4),(2,3),(2,4)]
- A compreensão de listas surgiu a partir da notação do:
pares xs ys = [(x,y) | x <- xs, y <- ys]
== do x <- xs
y <- ys
return (x,y)
3.3 Exceções: Either
- Para lidarmos com funções parciais ou que geram
exceções, podemos utilizar o Maybe.
- Porém, ele apenas indica que houve um problema
na avaliação das funções, mas não diz qual foi ele.
- Um tipo que generaliza o
Maybee permite reportar
o ponto que ocorreu a falha é o Either:
data Either a b = Left a | Right b
- Podemos definir
Leftcomo o log do erro eRight
como o valor esperado, caso tudo dê certo.
- A instância de Functor age apenas no valor da direita:
instance Functor (Either a) where
fmap f (Left x) = Left x
fmap f (Right x) = Right (f x)
- Similar ao
Maybe, a instância de Applicative
propaga o Left e aplica a função no Right:
instance Applicative (Either a) where
pure x = Right x
(Left f) <*> _ = Left f
_ <*> (Left x) = Left x
(Right f) <*> (Right x) = Right (f x)
- A instância de Monad também é similar ao
Maybe:
instance Monad (Either a) where
(Left x) >>= f = Left x
(Right x) >>= f = f x
- Com isso podemos fazer:
safeDiv :: (Show a, Eq a, Floating a) => a -> a -> Either String a
safeDiv a b
| b == 0 = Left ("Divisao por zero: " ++ show a ++ "/" ++ show b)
| otherwise = Right (a/b)
safeLog :: (Show a, Ord a, Eq a, Floating a) => a -> Either String a
safeLog x
| x <= 0 = Left ("Log invalido: " ++ show x)
| otherwise = Right (log x)
safeAdd :: Floating a => a -> a -> Either String a
safeAdd a b = Right (a+b)
safeExpr1, safeExpr2 :: Either String Double
safeExpr1 = do q <- safeDiv 10 (-2)
l <- safeLog q
safeAdd 2 q
safeExpr2 = do q <- safeDiv 10 0
safeAdd 2 q
print safeExpr1
print safeExpr2
3.4 Experiment no Glot.io
4 Efeitos Colaterais: Read Only
No início do curso revisamos as definições de funções puras e impuras. Recordando, uma função é pura quando ela não apresenta efeitos colaterais e o seu valor de retorno depende apenas dos seus próprios parâmetros.
Considere o seguinte código em C:
int y;
int f_read (int x) {
return x + y;
}
int g_read (int x) {
return x * y;
}
int h_read (int a, int b) {
int vf = f_read(a);
int vg = g_read(b);
return (vf + vg) != 0;
}
As funções f_read, g_read e h_read são impuras pois elas
dependem de um valor que não é um de seus argumentos. É verdade que,
em geral, queremos ficar longe de códigos semelhantes ao código acima
(variáveis globais são do mal!). Contudo, em alguns casos muito
específicos, este tipo de construção pode ser útil. Por exemplo, para
manter constantes, parâmetros de execução, informações de conexão a um
recurso compartilhado usado por diversas funções diferentes, etc. Nós
queremos fazer algo parecido com o código em C acima de maneira
puramente funcional.
Para reunir todo o contexto das informações de execução globais (ou, em outras palavras, representar as variáveis globais), vamos criar um tipo de dados:
newtype Globais = Globais {
y :: Int
-- Aqui você poderia adicionar todas as variáveis extras necessárias
-- no contexto global do seu programa
}
Agora, podemos escrever novas funções em Haskell, semelhantes às funções descritas em C acima, como:
f_read0 :: Int -> Globais -> Int
f_read0 x gl = x + y gl
g_read0 :: Int -> Globais -> Int
g_read0 x gl = x * y gl
h_read0 :: Int -> Int -> Globais -> Bool
h_read0 a b gl = (vf + vg) /= 0
where
vf = f_read0 a gl -- Passando o contexto gl para f_read0
vg = g_read0 b gl -- Passando o contexto gl para g_read0
A parte não muito prática dessa implementação é que quando queremos
fazer chamadas seguidas de funções que dependem do contexto global,
precisamos fazer na mão de forma explícita a passagem do contexto, como indicado na função h_read0.
Vamos tentar melhorar isto!
Para começar, vamos reparar que a assinatura de todas as funções que
usam este contexto global é finalizada em Globais -> a, onde esse a
varia conforme a função. Vamos abstrair este tipo para e -> a e
colocar isto dentro de um ADT. Fica assim:
data Reader e a = Reader (e -> a)
Reader guarda uma função do tipo e -> a. No caso específico do
exemplo acima, o Reader guardaria uma função que dado o contexto das
globais (definido pelo ADT Globais) devolve um valor a, onde o
significado de a varia conforme a função.
Agora podemos começar a definir algumas funções auxiliares. A função
runReader, dado um contexto e aplica a função contida no Reader
a esse contexto e devolve o resultado:
runReader :: Reader e a -> e -> a
runReader (Reader f) e = f e
E a função ask permite que pergutemos o conteúdo de um contexto
passado a um Reader. Sua utilidade será revelada em breve!
ask :: Reader e e
ask = Reader id
Note ao utilizar ask em conjunto com a função runReader, extraímos o contexto:
runReader ask e = runReader (Reader id) e = id e = e
Com isto estamos prontos para criar algumas instâncias para o nosso
tipo Reader.
Como fica a instância de Functor para o tipo Reader?
O problema que queremos responder é o de quando temos um contêiner que contém uma função e queremos aplicar uma função sobre ela. Em outras palavras, quando a função interna for aplicada a um parâmetro (contexto), queremos pegar seu valor de retorno e aplicar uma outra função sobre este resultado.
Uma primeira implementação poderia ser então:
data Reader e a = Reader (e -> a)
instance Functor (Reader e) where
-- fmap :: (a -> b) -> Reader e a -> Reader e b
fmap f (Reader g) = Reader $ \e -> f (g e)
Mas, se repararmos bem, essa implementação é simplesmente a composição de funções! Ou seja:
data Reader e a = Reader (e -> a)
instance Functor (Reader e) where
-- fmap :: (a -> b) -> Reader e a -> Reader e b
fmap f (Reader g) = Reader (f . g)
E a instância de Applicative?
Neste caso temos uma função que está em um contexto (Applicative) e um valor no mesmo contexto. Para extraí-los precisamos efetuar dois passos:
- O
Readerque contém a função (operando à esquerda) deve ser executado com um contexto para obter a função a ser aplicada - O
Readerque contém o valor (operando à direita) deve ser executado com um contexto para obter o parâmetro da função a ser aplicada
A implementação que efetua esses passos pode ser então escrita como:
instance Applicative (Reader e) where
-- pure :: a -> Reader e a
pure x = Reader (\e -> x)
-- (<*>) :: Reader e (a -> b) -> Reader e a -> Reader e b
rFun <*> rV = Reader $ \e ->
let f = runReader rFun e -- Passo 1
v = runReader rV e in -- Passo 2
f v -- A aplicação propriamente dita
E agora, para criar a instância de Monad seguimos uma
ideia muito parecida com aquela do applicative, com a diferença de que
apenas o valor (operando à esquerda do (>>=)) precisa ser
executado com um contexto para ser extraído:
instance Monad (Reader e) where
-- (>>=) :: Reader e a -> (a -> Reader e b) -> Reader e b
rV >>= f = Reader $ \e ->
let v = runReader rV e -- :: a
r = f v in -- :: Reader e b
runReader r e
Agora estamos prontos para reescrever a função f_read0:
data Reader e a = Reader (e -> a)
f_read0 :: Int -> Globais -> Int
f_read0 x gl = x + y gl
f_read1 :: Int -> Reader Globais Int
f_read1 x = do
g <- ask
return $ x + y g
Antes de olharmos com cuidado como vamos usar esta função, vamos
reparar em algumas coisas. Primeiramente veja que o tipo foi
alterado. A parte da assinatura da função Globais -> Int se tornou
Reader Globais Int. Além disto, como agora o contexto está dentro do
Reader, precisamos chamar a função ask para pegar o contexto e em
seguida chamamos a função y (definida dentro do ADT Globais usando
record syntax) para pegar o valor que estamos interessados. Note
também que ao final usamos a função return, que não é nada mais do
que a função pure com um nome diferente. Isto é necessário pois como
o valor x + y g é Int, e o tipo do retorno de f_read1 é Reader Globais Int, precisamos colocar o resultado no contexto esperado
antes de devolver.
Para usar (ambas as versões) podemos fazer:
> f_read0 3 (Globais 5) -- versão original
8
> runReader (f_read1 3) (Globais 5) -- versão com Reader
8
As funções g_read0 e h_read0 agora podem ser reescritas para ficarem:
g_read1 :: Int -> Reader Globais Int
g_read1 x = do
gl <- ask
return $ x * y gl
h_read1 :: Int -> Int -> Reader Globais Bool
h_read1 a b = do
vf <- f_read1 a -- O contexto é passado automaticamente!
vg <- g_read1 b
return $ (vf + vg) /= 0
Note que o contexto das globais, utilizado na função h_read1 é
passado automaticamente para as funções f_read1 e g_read1!
Compare as duas versões abaixo:
h_read0 :: Int -> Int -> Globais -> Bool
h_read0 a b gl = (vf + vg) /= 0
where
vf = f_read0 a gl
vg = g_read0 b gl
h_read1 :: Int -> Int -> Reader Globais Bool
h_read1 a b = do
vf <- f_read1 a -- O contexto é passado automaticamente!
vg <- g_read1 b
return $ (vf + vg) /= 0
Como que isto está funcionando? Que bruxaria é essa? Não é feitiçaria,
é tecnologia! Tudo está embutido no funcionamento do (>>=) que
criamos para o Reader que repassa o contexto para nós. Para explicar
em detalhes, vamos primeiramente reescrever a função f_read1 para
que ela não use os açúcares sintáticos da notação do:
-- Versão com açúcar
f_read1 :: Int -> Reader Globais Int
f_read1 x = do
g <- ask
return $ x + y g
-- Versão diet
f_read1' :: Int -> Reader Globais Int
f_read1' x = ask >>= \g -> return $ x + y g
Vamos agora olhar, passo a passo, a execução da expressão runReader (f_read1' 3) (Globais 5):
runReader (f_read1' 3) (Globais 5)
-- Pela definição de f_read1'
runReader (ask >>= \g -> return $ 3 + y g) (Globais 5)
-- Pela definicao de ask
runReader ((Reader id) >>= \g -> return $ 3 + y g) (Globais 5)
-- Pela definição do >>=
runReader (Reader $ \e ->
let v = runReader (Reader id) e
r = (\g -> return $ 3 + y g) v in
runReader r e) (Globais 5)
-- Pela definição de runReader: `runReader (Reader f) e = f e`
(\e ->
let v = runReader (Reader id) e
r = (\g -> return $ 3 + y g) v in
runReader r e) (Globais 5)
-- Redução beta em e
let v = runReader (Reader id) (Globais 5)
r = (\g -> return $ 3 + y g) v in
runReader r (Globais 5)
-- Pela definição de runReader
let v = id (Globais 5)
r = (\g -> return $ 3 + y g) v in
runReader r (Globais 5)
-- Pela definição de id
let v = Globais 5
r = (\g -> return $ 3 + y g) v in
runReader r (Globais 5)
-- Substituindo v em r
let v = Globais 5
r = (\g -> return $ 3 + y g) (Globais 5) in
runReader r (Globais 5)
-- Redução beta em g
let v = Globais 5
r = return $ 3 + y (Globais 5) in
runReader r (Globais 5)
-- Pela definição de return
let v = Globais 5
r = Reader \e -> 3 + y (Globais 5) in
runReader r (Globais 5)
-- Substituindo r
let v = Globais 5
r = Reader $ \e -> 3 + y (Globais 5) in
runReader (Reader $ \e -> 3 + y (Globais 5)) (Globais 5)
-- Pela definição de runReader
let v = Globais 5
r = Reader $ \e -> 3 + y (Globais 5) in
(\e -> 3 + y (Globais 5)) (Globais 5)
-- Redução beta em e
let v = Globais 5
r = Reader $ \e -> 3 + y (Globais 5) in
3 + y (Globais 5)
-- Pela definição de y, no ADT Globais
let v = Globais 5
r = Reader $ \e -> 3 + y (Globais 5) in
3 + 5
-- E finalmente:
8
E para arrematar, podemos criar uma nova função chamada askFor com a
seguinte implementação:
askFor :: (e -> a) -> Reader e a
askFor f = fmap f ask
E com ela podemos empetecar a implementação de f_read1 para:
f_read2 :: Int -> Reader Globais Int
f_read2 x = do
vy <- askFor y
return $ x + vy
4.1 Experimente online no Glot.io
5 Efeitos Colaterais: Write Only
- Considere o seguinte código:
isEven x = even x
not' b = not b
isOdd x = (not' . isEven) x
- Digamos que eu gostaria de gravar o traço de execução para verificar as funções que são chamadas. Logo eu gostaria que:
> isOdd 3
(True, " isEven not' ")
- Podemos criar novas versões de nossas funções:
isEven x = (even x, " isEven ")
not' b = (not b, " not' ")
isOdd x = (not' . isEven) x -- ops
- Não é mais possível compor as funções
isEvenenot'…
isEven x = (even x, " isEven ")
not' b = (not b, " not' ")
isOdd x = let (b1, trace1) = isEven x
(b2, trace2) = not' b1
in (b2, trace1 ++ trace2)
- Nada prático…
- As assinaturas dessas funções seguem o formato
a -> (b, String):
isEven :: Integer -> (Bool, String)
isEven x = (even x, " isEven ")
not' :: Bool -> (Bool, String)
not' b = (not b, " not' ")
isOdd :: Integer -> (Bool, String)
isOdd x = let (b1, trace1) = isEven x
(b2, trace2) = not' b1
in (b2, trace1 ++ trace2)
- Fazendo
m = (a, String), temosa -> m b🤔
- Vamos definir o tipo
Writere algumas funções auxiliares:
data Writer w a = Writer a w
runWriter :: Writer w a -> (a, w)
runWriter (Writer a w) = (a, w)
tell :: w -> Writer w ()
tell s = Writer () s
O w do tipo Writer representa o tipo do efeito colateral desejado,
no nosso exemplo, a String.
- A instância de Functor simplesmente aplica uma função no valor sem causar um efeito colateral.
instance (Monoid w) => Functor (Writer w) where
-- fmap :: (a -> b) -> Writer w a -> Writer w b
fmap f (Writer a w) = Writer (f a) w
Hmmm…Monoid 🤔
- Para a instância de Applicative a função
purecria um valor sem efeito colateral. No nosso exemplo, a String vazia! O operador aplicar simplesmente aplica a função no valor e concatena os efeitos!
instance (Monoid w) => Applicative (Writer w) where
-- pure :: a -> Writer w a
pure x = Writer x mempty
-- (<*>) :: Writer w (a -> b) -> Writer w a -> Writer w b
(Writer f m1) <*> (Writer a m2) = Writer (f a) (m1 <> m2)
- A instâcia de Monad aplica a função no valor puro de
nosso Writer, gerando um efeito colateral…
instance (Monoid w) => Monad (Writer w) where
-- (Writer w a) -> (a -> Writer w b) -> (Writer w b)
(Writer a w) >>= k = let (b, w') = runWriter (k a)
in Writer b (w <> w')
…em seguida retorna o valor com os efeitos compostos.
- Dessa forma nosso exemplo fica:
isEvenW' :: Integer -> Writer String Bool
isEvenW' x = do tell " even "
return (even x)
notW' :: Bool -> Writer String Bool
notW' b = do tell " not "
return (not b)
- E podemos definir
isOddW'com o operador
de composição de Monads >=>:
-- (>=>) :: (a -> m b) -> (b -> m c) -> (a -> m c)
isOddW' :: Integer -> Writer String Bool
isOddW' = (isEvenW' >=> notW')
5.1 Experimente online no Glot.io
6 Efeitos Colaterais: Read and Write
- Considere o seguinte problema: tenho uma árvore do tipo
Tree Chare quero converter para umaTree Intsendo que os nós folhas receberão números de[0..]na sequência de visita:
data Tree a = Leaf a | Node (Tree a) (Tree a)
deriving Show
tree :: Tree Char
tree = Node (Node (Leaf 'a') (Leaf 'b')) (Leaf 'c')
f tree = Node (Node (Leaf 0) (Leaf 1)) (Leaf 2)
6.1 Estado
Um esqueleto dessa função seria:
data Tree a = Leaf a | Node (Tree a) (Tree a)
deriving Show
rlabel :: Tree a -> Tree Int
rlabel (Leaf _) = Leaf n
rlabel (Node l r) = Node (rlabel l) (rlabel r)
-
Queremos que
nseja uma variável de estado, ou seja, toda vez que a utilizarmos ela altere seu estado! -
Mas somos puros e imutáveis! Como podemos resolver isso?
- Uma ideia é incorporar o estado atual na declaração da função:
rlabel :: Tree a -> Int -> (Tree Int, Int)
rlabel (Leaf _) n = (Leaf n, n + 1)
rlabel (Node l r) = (Node l' r', n'')
where
(l', n') = rlabel l n -- altera o estado de n
(l'', n'') = rlabel r n' -- altera o estado de n'
Com isso podemos chamar:
> rlabel tree 0
=> (Node l' r', n'')
> (l', n') = rlabel (Node (Leaf 'a') (Leaf 'b')) 0
=> (Node l' r', n'')
> (l', n') = rlabel (Leaf 'a') 0
=> (Leaf 0, 1)
> (r', n'') = rlabel (Leaf 'b') 1
=> (Leaf 1, 2)
> (r, n'') = rlabel (Leaf 'c') 2
=> (Leaf 2, 3)
(Node (Node (Leaf 0) (Leaf 1)) (Leaf 2), 3)
- Vamos generalizar o tipo
Tree a -> Int -> (Tree Int, Int)
t -> (a -> (b, a))
- A segunda parte me lembra algo…🤔
- O tipo
Readeréa -> b, o tipoWriteré(a, b):
t -> (a -> (b, a))
t -> Reader a (Writer a b)
- Faz sentido, queremos um valor que pode ser lido e alterado: Reader-Writer.
6.2 Transformador de Estado
- Vamos definir o tipo
Statecomo:
-- = Reader s (Writer s a)
data State s a = State (s -> (a, s))
Com isso a assinatura de rlabel pode se tornar:
rlabel :: Tree a -> State Int (Tree Int)
- Um transformador de estado pode ser visto como uma caixa que recebe um estado e retorna um valor e um novo estado:

Figure 2: Transformador de estado
- Podemos pensar também em um transformador de estados que, além de um estado, recebe um valor para agir dentro do ambiente que ele vive:

Figure 3: Transformador de estado
- Vamos criar uma função auxiliar para aplicar um transformador de
estado em um estado (que está encapsulado no construtor
State):
runState :: State s a -> s -> (a, s)
runState (State f) s = f s
Essencialmente, as instâncias de Functor, Applicative, Monad são
muito parecidas com as do Reader.
- A ideia geral de um Functor ST é que ele defina como aplicar uma
função pura do tipo
a -> bna parte do valor do resultado de umST a, transformando-o efetivamente em um tipoST b:
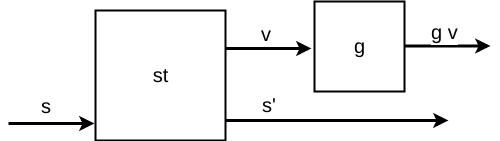
Figure 4: Functor ST
Com isso temos:
instance Functor (State s) where
-- fmap :: (a -> b) -> State s a -> State s b
fmap f (State g) = State (\s -> let (a, s') = g s
in (f a, s'))
- criamos uma função que gera o valor
ae um novo estado e, então, retornaf acom esse novo estado.
-
Esse Functor promete aplicar uma função pura apenas no valor de saída do transformador de estado, sem influenciar o estado.
-
Se em
rlabeleu quiser gerar rótulos pares, poderia aplicarfmap (*2)a função de estado.
-
A classe Applicative define formas de combinar computações sequenciais puras dentro de computações que podem sofrer efeitos colaterais.
-
Embora cada computação na sequência possa alterar o estado
s, o valor final é a computação dos valores puros.
A definição de pure cria um transformador de estado puro, ou seja, que
não altera o estado:
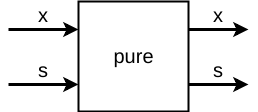
Figure 5: pure ST
Então definimos:
instance Applicative (State s) where
-- pure :: a -> State s a
pure x = State (\s -> (x, s))
- A definição do operador
(<*>)define a sequência de mudança de estados pelos transformadores e a combinação dos valores finais como um resultado único:
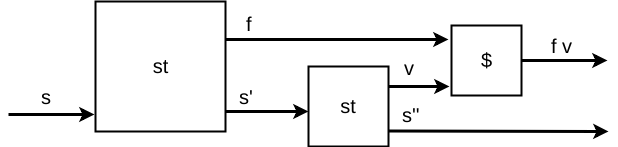
Figure 6: <*> ST
Então definimos:
instance Applicative (State s) where
-- (<*>) :: State s (a -> b) -> State s a -> State s b
sab <*> sa = State (\s -> let (f, s1) = runState sab s
(a, s2) = runState sa s1
in (f a, s2))
Como primeiro passo é preciso recuperar a função f, o que altera
o estado. Em seguida, recuperamos a utilizando o novo estado, gerando
o próximo estado. Finalmente, aplicamos f a e retornamos o último estado
gerado.
No nosso exemplo de rlabel, podemos imaginar algo como:
pure Leaf <*> sInc
- Se
sIncé um transformador de estados que incrementa um contador, então:pure Leafé aplicado no estado atualsretornando ele mesmo (pois é puro)sIncé aplicado asretornando um novo estado com o contador incrementado:(Leaf n, n + 1)
No caso de Monads, queremos definir um operador (>>=) que se
comporte como:
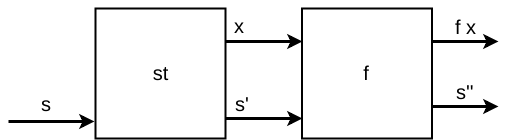
Figure 7: Monad ST
-
Podemos observar que o operador bind age de forma similar a
(<*>), porém cada encadeamento gera um novo transformador de estado que pode depender do valor retornado pelo transformador anterior. -
Ou seja, um Monad ST pode ser usado quando queremos gerar novos transformadores dependendo do valor de retorno de outro.
Com isso definimos:
instance Monad (State s) where
-- (>>=) :: State s a -> (a -> State s b) -> State s b
sa >>= f = State (\s -> let (a, s1) = runState sa s
sb = f a
in runState sb s1)
Primeiro recuperamos o valor de a, gerando um novo estado.
Em seguida, aplicamos f a que gera um novo State que é
executado com o último estado gerado.
No nosso exemplo de rlabel, podemos imaginar algo como:
do n <- sInc
return (Leaf n)
para alterar o rótulo de um nó folha.
6.3 Applicative rlabel
data Tree a = Leaf a | Node (Tree a) (Tree a)
deriving Show
rlabel :: Tree a -> Int -> (Tree Int, Int)
rlabel (Leaf _) n = (Leaf n, n+1)
rlabel (Node l r) n = let (l', n1) = rlabel l n
(r', n2) = rlabel r n1
in (Node l' r', n2)
A versão completa do Applicative rlabel fica:
alabel :: Tree a -> State Int (Tree Int)
alabel (Leaf _) = pure Leaf <*> sInc
alabel (Node l r) = pure Node <*> alabel l <*> alabel r
mlabel :: Tree a -> State Int (Tree Int)
mlabel (Leaf _) = do n <- sInc
return (Leaf n)
mlabel (Node l r) = do l' <- mlabel l
r' <- mlabel r -- e se eu trocar a ordem?
return $ Node l' r'
Finalmente, a definição de sInc fica:
sInc :: State Int Int
sInc = S (\n -> (n, n+1))
Para aplicar essas funções, devemos fazer:
tree :: Tree Char
tree = Node (Node (Leaf 'a') (Leaf 'b')) (Leaf 'c')
newtype ST a = S (State -> (a, State))
app :: ST a -> State -> (a, State)
app (S st) s = st s
sInc :: ST Int
sInc = S (\n -> (n, n+1))
alabel :: Tree a -> ST (Tree Int)
alabel (Leaf _) = pure Leaf <*> sInc
alabel (Node l r) = pure Node <*> alabel l <*> alabel r
> stTree = alabel tree -- cria transformador de estado
> app stTree 0 -- começa a contar do 0
(Node (Node (Leaf 0) (Leaf 1)) (Leaf 2), 3)
6.4 Experimente online no Glot.io
7 Efeitos Colaterais: IO
-
Conforme discutimos anteriormente, funções de entrada e saída de dados são impuras pois alteram o estado atual do sistema.
-
A função
getCharcaptura um caracter do teclado. Se eu executar tal função duas vezes, o valor da função não necessariamente será igual. -
A função
putCharescreve um caracter na saída padarão (ex.: monitor). Se eu executar duas vezes seguidas com a mesma entrada, a saída será diferente.
Basicamente, as funções de entrada e saída alteram estado, ou seja:
newtype IO a = newtype ST a = State -> (a, State)
com a definição de estado sendo:
type State = Environment
o estado sendo o ambiente, sistema operacional, o mundo computacional que ele vive.
Com isso, tudo que fizemos até agora é suficiente para trabalharmos com IO sem afetar a pureza dos nossos programas:
getchar :: IO Char
putChar :: Char -> IO ()
Se eu fizer:
do putChar 'a'
putChar 'a'
Na verdade ele estará fazendo algo como:
(_, env') = putChar 'a' env
(_, env'') = putChar 'a' env'
-
No Haskell chamamos as funções de entrada e saída como ações de IO (_IO actions _).
-
As funções básicas são implementadas internamente de acordo com o Sistema Operacional
Vamos trabalhar inicialmente com três ações básicas:
-- recebe um caracter da entrada padrão
getChar :: IO Char
-- escreve um caracter na saída padrão
putChar :: Char -> IO ()
-- retorna um valor puro envolvido de uma ação IO
return :: a -> IO a
Em vez de capturar apenas um caracter, podemos capturar uma linha
inteira de informação. Podemos escrever getLine da seguinte
maneira:
getLine :: IO String
getLine = do x <- getChar
if x == '\n' then
return []
else
do xs <- getLine
return (x:xs)
A função return não se comporta como em outras linguagens!
Lembre-se: return apenas pega um valor puro e o coloca no em um
contexto. Ele não interrompe a execução.
7.1 Exercício 2
Escreva as instruções do else como Applicative
getLine :: IO String
getLine = do x <- getChar
if x == '\n' then
return []
else
do xs <- getLine
return (x:xs)
A função inversa escreve uma String na saída padrão:
putStr :: String -> IO ()
putStr [] = return ()
putStr (x:xs) = do putChar x
putStr xs
putStrLn :: String -> IO ()
putStrLn xs = do putStr xs
putChar 'n'
7.2 Exercício 3
Escreva a função putStrLn usando Applicative.
putStrLn :: String -> IO ()
putStrLn xs = do putStr xs
putChar '\n'
8 Funções de alta ordem para Monads
- As funções de alta ordem possuem versões para Monads na
biblioteca
Control.Monad:
mapM :: Monad m => (a -> m b) -> [a] -> m [b]
mapM f [] = return []
mapM f (x:xs) = do y <- f x
ys <- mapM f xs
return (y:ys)
- Digamos que tenho a seguinte função:
conv :: Char -> Maybe Int
conv c | isDigit c = Just (digitToInt c)
| otherwise = Nothing
- Podemos aplicar
mapMpara obter:
> mapM conv "1234"
Just [1,2,3,4]
> mapM conv "12a4"
Nothing
- Também temos a versão monádica de
filter:
filterM :: Monad m => (a -> m Bool) -> [a] -> m [a]
filterM p [] = return []
filterM p (x:xs) = do b <- p x
ys <- filter M p xs
return (if b then x:ys else ys)
- Podemos gerar o conjunto das partes com essa função e o Monad List:
> filterM (\x -> [True, False]) [1,2,3]
[[1,2,3],[1,2],[1,3],[1],[2,3],[2],[3],[]]
🤨 🤨 🤨
-
Lembrando que o Monad listas representa uma computação não deterministica.
-
filterM: “para um certo elemento da lista, quais as possibilidades de selecioná-lo?” -
\_ -> [False, True]diz que cada elemento pode existir ou não na lista!
- Para cada elemento da lista, ele cria duas ramificações: uma em que aquele elemento existe e outra que ele não existe.
[]
/ \
[1] []
/ \ / \
[1,2] [1] [2] []
...
filterseleciona elementos de uma listafilterMseleciona possíveis eventos de uma sequência de computações
- Considere esse outro exemplo:
f x | even x = [False]
| otherwise = [True, False]
Qual a saída para filterM f [1, 2, 3]?
filterM f [1, 2, 3]
Saída:
- Nesse caso geramos a combinação dos elementos ímpares.
- E se nossa função for:
Qual a saída para
g x | x == 0 = Nothing | even x = Just True | otherwise = Just FalsefilterM g [1, 2, 3, 0, 4]efilterM g [1, 2, 3, 4]?
filterM g [1, 2, 3, 0, 4]
Saída:
filterM g [1, 2, 3, 4]
Saída:
- o
Nothingindica que a lista é inválida e não deve ser processada.
- E com essa função?
h :: Int -> Writer String Bool
h x | x == 0 = writer (True, "Invalid! ")
| even x = writer (True, "Valid! ")
| otherwise = writer (False, "Discarded!" )
Qual a saída para filterM h [1, 2, 3, 0, 4] e filterM h [1, 2, 3, 4]?
filterM h [1, 2, 3, 0, 4]
Saída:
filterM h [1, 2, 3, 4]
Saída:
8.1 Monads
9 Para saber mais

- Functors, Applicatives e Monads
- [GH] 12
- [SGS] 14
- [ML] 11, 12

- [GH] 14
- [SGS] 13, 14, 15
- [ML] 11
- State IO e Leitura de Arquivos
10 Disclaimer
Estes slides foram preparados para os cursos de Paradigmas de Programação e Desenvolvimento Orientado a Tipos na UFABC.
Este material pode ser usado livremente desde que sejam mantidos, além deste aviso, os créditos aos autores e instituições.
