Finger Trees
Playlists
- Desta aula: …
- Do curso: https://www.youtube.com/playlist?list=PLYItvall0TqJ25sVTLcMhxsE0Hci58mpQ
1 Introdução

Figure 1: Fonte: http://weddbook.com
Finger Trees é uma daquelas estruturas de dados que depois que você realmente entende, você fica boquiaberto por algum tempo (eu pelo menos fiquei):
- Pela sua simplicidade e eficiência;
- Pelo seu poder de adaptação.
Finger Trees são uma (baita) variação de uma outra estrutura de dados muito conhecida no mundo imperativo chamada de Árvores 2-3.
Disclaimer: Esta aula é fortemente baseada no paper que apresentou as FingerTrees ao mundo em 2006. Boa parte do código foi “adaptada” do paper original para facilitar o entendimento. Apesar de funcional (sem trocadilhos), o código que apresentamos não é otimizado. As referências nos slides finais têm links para implementações otimizadas em Haskell e outras linguagens.
2 Relembrando: Árvores 2-3
Árvores 2-3 são árvores balanceadas que servem de ponto de partida para várias outras:
- Árvores rubro-negras
- Árvores B, B+, B*
- Árvores 2-3-4
- E, quem diria, Finger Trees
Árvores 2-3 são árvores onde cada nó pode ter 2 ou 3 filhos
- E por consequência podem guardar 2 valores por nó.
Algumas variações guardam os elementos nos nós internos e outras apenas nas folhas. Aqui estamos interessados na variação que guarda os elementos nas folhas.
- Na verdade é muito mais parecido com uma árvore B+ sem os links que encadeiam as folhas
Aqui está uma foto:

2.1 Exemplo de inserção Árvores 2-3
- Experimente a sequência: S, E, A, R, C, H, X, M

Ok, tomando novamente a nossa figura de exemplo.
- A altura é uniforme e o acesso a qualquer elemento leva tempo \(O(\lg n)\) (pois a árvore é balanceada).
- Contudo para algumas aplicações, o acesso às extremidades é muito mais comum do que o acesso aos elementos centrais.
- A intenção aqui é usar a árvore para modelar ao mesmo tempo:
- Pilhas
- Filas
- Deques
Poderíamos modelar a árvore da seguinte maneira em Haskell:
data Tree a = Zero a | Succ (Tree (Node a))
data Node a = Node2 a a | Node3 a a a
Preste muita atençao ao tipo Tree. Ele usa uma técnica chamada de
tipo não regular (non-regular type). É essencialmente a mesma
técnica que usamos para representar os números de Peano. Gaste um
tempinho para realmente entender o que está acontecendo e quais são
os tipos dos nós da árvore.
3 Finger Trees
Uma estrutura que permite acesso eficiente aos nós de uma árvore próximos de uma determinada posição é chamada de Finger .
- Termo criado por Guibas et al. em 1997.
- Em uma linguagem imperativa, fingers tomam a forma de um ponteiro.
- Em uma linguagem funcional, vamos tranformar a nossa estrutura de árvore em algo parecido como que fizemos com Zippers.
Para dar acesso rápido aos elementos no início e no fim da nossa sequência, vamos instalar fingers nas extremidades direita e esquerda da árvore.
3.1 Pendurando a árvore
Imagine se pegássemos a árvore de exemplo e a “pendurássemos” apenas pelas suas extremidades:

Note que esse tipo de transformação é possível pois a nossa árvore original era uniforme na altura (como toda árvore 2-3).

Para finalmente construírmos a nossa finger tree, a ideia em seguida é mesclar os nós destacados em vermelho em um só nó.
- O conjunto dos nós em vermelho forma a espinha da nossa finger tree.
- Note que conforme descemos na espinha, nós estamos na verdade indo das folhas para a raiz!
No site dos autores do paper da Finger Tree, eles têm figuras de algumas árvores maiores.

Como representar esse estrupício em Haskell?
3.2 Representando uma Finger Tree
data Digit a where
One :: a -> Digit a
Two :: a -> a -> Digit a
Three :: a -> a -> a -> Digit a
Four :: a -> a -> a -> a -> Digit a
data Node a where
Node2 :: a -> a -> Node a
Node3 :: a -> a -> a -> Node a
data FingerTree a where
Empty :: FingerTree a
-- Como digits são >0 precisamos tratar
-- árvores de tamanho 1.
Single :: a -> FingerTree a
-- A cada nível da espinha, temos como raiz uma
-- do tipo FingerTree (Node a)^n
-- left spine right
Deep :: Digit a -> FingerTree (Node a) -> Digit a -> FingerTree a
- Aqui percebemos a primeira diferença entre Finger Trees e árvores 2-3: é permitido que um nó armazene de 1 a 4 elementos.
- Essa modificação é importante para garantirmos os limites de complexidade amortizados que queremos alcançar.
O tipo Digit tem esse nome pois Finger Trees se encaixam na categoria de representação numérica [CO] que engloba as estrutura de dados baseadas em um sistema numérico.
3.3 Codificando a árvore de exemplo
level3 :: FingerTree a
level3 = Empty
level2 :: FingerTree (Node Char)
level2 = Deep l level3 r
where
l = Two (Node2 'i' 's')
(Node2 'i' 's')
r = Two (Node3 'n' 'o' 't')
(Node2 'a' 't')
level1 :: FingerTree Char
level1 = Deep l level2 r
where
l = Two 't' 'h'
r = Three 'r' 'e' 'e'
hinzePatterson :: FingerTree Char
hinzePatterson = level1
3.4 Experimente no Repl.it
Experimente o código dessa seção no Repl.it abaixo:
4 Deques
Agora que temos a representação da árvore, vamos ver uma primeira aplicação de Finger Trees como deques (double ended queue).
O que queremos é algo melhor em termos de desempenho do que já tínhamos com a implementação usando uma lista ou um par de listas.
Deques via de regra dão suporte as seguintes operações de consulta e modificação:
head- consulta extremidade esquerdalast- consulta extremidade direitacons- adiciona à extremidade esquerdasnoc- adiciona à extremidade direitatail- remove extremidade esquerdainit- remove extremidade direita
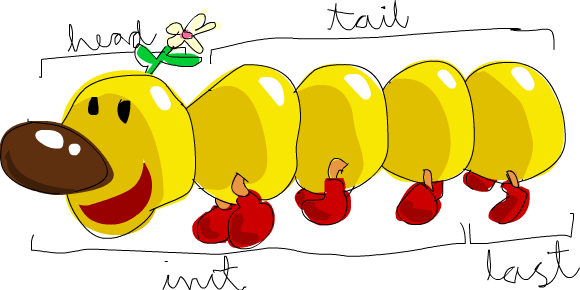
Figure 2: LYAH
4.1 cons A.K.A. <|
-- Imagine o símbolo <| indicando que a operação é na
-- extremidade esquerda
infixr 5 <|
(<|) :: a -> FingerTree a -> FingerTree a
-- Caso inicial e trivial: cria uma árvore single
x <| Empty = Single x
-- Já temos o suficiente para uma árvore de verdade
x <| Single y = Deep (One x) Empty (One y)
-- Adicionar um novo elemento é trivial exceto no caso
-- da árvore já conter 4 elementos. Neste caso,
-- jogamos 3 para um um novo nó e deixamos 2 para trás.
x <| Deep (Four a b c d) s r =
Deep (Two x a) (Node3 b c d <| s) r
-- Se chegou aqui então tem espaço no nó inicial
x <| (Deep l s r) = Deep (concatL l x) s r
Para facilitar a manipulação de Digit, criamos algumas funções
auxiliares:
-- Equivalente ao cons para Digit
concatL :: Digit a -> a -> Digit a
concatL (One a) x = Two x a
concatL (Two a b) x = Three x a b
concatL (Three a b c) x = Four x a b c
concatL Four{} _ = error "Digit overflow :)"
-- Equivalente ao snoc para Digit
concatR :: Digit a -> a -> Digit a
concatR (One a) x = Two a x
concatR (Two a b) x = Three a b x
concatR (Three a b c) x = Four a b c x
concatR Four{} _ = error "Digit overflow :)"
4.2 snoc A.K.A. |>
-- A implementação de |> é simétrica à de <|. Imagine o
-- símbolo |> indicando que a operação é na extremidade
-- direita. Note que por esta razão a ordem dos
-- parâmetros é invertida.
infixl 5 |>
(|>) :: FingerTree a -> a -> FingerTree a
Empty |> x = Single x
Single y |> x = Deep (One y) Empty (One x)
Deep l s (Four a b c d) |> x =
Deep l (s |> Node3 a b c) (Two d x)
(Deep l s r) |> x =
Deep l s (concatR r x)
4.3 Construindo a partir de uma lista
Agora ficou fácil, inclusive, criar uma árvore a partir de uma lista:
treeFromList :: [a] -> FingerTree a
treeFromList = foldr (<|) Empty
Na verdade, poderíamos usar qualquer Foldable! A implementação seria:
fromFoldable :: Foldable f => f a -> FingerTree a
fromFoldable = foldr (<|) Empty
4.4 Qual a complexidade de cons e snoc?
Uma primeira análise pode chegar a conclusão de que o custo de
cons e snoc é \(O(\lg n)\). Mas a história toda é um pouco mais
complicada…
- De fato o pior caso é \(O(\lg n)\), mas o caso típico ficou muito mais barato!
- Vamos rever o código…
(<|) :: a -> FingerTree a -> FingerTree a
x <| Empty = Single x -- Caso 1
x <| Single y = Deep (One x) Empty (One y) -- Caso 2
x <| Deep (Four a b c d) s r = -- Caso 3
Deep (Two x a) (Node3 b c d <| s) r
x <| (Deep l s r) = Deep (concatL l x) s r -- Caso 4
- Note que os casos 1, 2 e 4 rodam em tempo constante
- Para uma sequência de operações
cons, por exemplo, menos de \(\frac{1}{2}\) das operações caem no caso 3 (recursivo) no primeiro nível- O padrão dos casos para uma sequência de apenas
cons: 1, 2, 4, 4, 4, 3, 4, 4, 3, 4, 4, 3, …
- O padrão dos casos para uma sequência de apenas
- No segundo nível menos de \(\frac{1}{4}\)
- …
Logo o custo máximo para uma sequencia de \(m\) operações vai ser:
\[T = m + \frac{1}{2}m + \frac{1}{4}m + \frac{1}{8}m + \ldots < \sum_{i=0}^{\infty}\frac{1}{2^i}m = m\sum_{i=0}^{\infty}\frac{1}{2^i} = 2m\]
Assim o custo médio por operação é \(2\) e o custo amortizado por operação é \(O(1)\).
A verdade é que essa análise que fizemos é muito da safada. Para efetivamente (e formalmente) provar o custo amortizado das operações precisamos fazer a análise usando o método do banqueiro ou do físico.
A análise formal é bem mais complicada e é essencialmente a mesma utilizada por [CO] em sua implementação de deques implícitos.
- A diferença entre aquela implementação e esta é que nesta são substituídos pares por nós que podem conter 2 ou 3 elementos. Isso nos dará mais liberdade para implementar algumas operações adicionais como veremos adiante.
4.5 Views
Já temos implementações de cons e snoc. E, apesar das
implementações de head e last serem triviais, vamos matar
tudo junto utilizando Views .
Definimos uma view assim:
data View s a =
Nil -- s vazia, não há foco.
| ConsV a (s a) -- a é o foco, (s a) o "resto"
deriving Show
E criamos duas funções, uma que devolve a view à direita e outra à esquerda:
viewL :: FingerTree a -> View FingerTree a
viewR :: FingerTree a -> View FingerTree a
Suponha que tenhamos as funções viewL e viewR prontas. A
implementação das operações restantes do nosso deque são triviais:
head t =
case viewL t of
ConsV x _ -> x
Nil ->
error "head: empty"
init t =
case viewR t of
ConsV _ xs -> xs
Nil ->
error "init: empty"
last t =
case viewR t of
ConsV x _ -> x
Nil ->
error "last: empty"
tail t =
case viewL t of
ConsV _ xs -> xs
Nil ->
error "tail: empty"
4.6 Implementando viewL
Precisaremos de algumas funções auxiliares em Digit.
-- Primeiro elemento de um Digit
dFirst :: Digit a -> a
dFirst (One a) = a
dFirst (Two a _) = a
dFirst (Three a _ _) = a
dFirst (Four a _ _ _) = a
-- Cauda de um Digit
dTail :: Digit a -> Maybe (Digit a)
dTail One{} = Nothing
dTail (Two _ b) = Just $ One b
dTail (Three _ b c) = Just $ Two b c
dTail (Four _ b c d) = Just $ Three b c d
Também precisaremos, em alguns casos, usar os elementos de um
Digit para construir uma nova árvore.
digitToTree :: Digit a -> FingerTree a
digitToTree (One a) = Empty |> a
digitToTree (Two a b) = Empty |> a |> b
digitToTree (Three a b c) = Empty |> a |> b |> c
digitToTree (Four a b c d) = Empty |> a |> b |> c |> d
É um exercício interessante implementar Digit como uma instância
de Foldable e utilizar a função fromFoldable que vimos antes no
lugar de digitToTree!
viewL :: FingerTree a -> View FingerTree a
viewL Empty = Nil -- Caso trivial 1
viewL (Single x) = ConsV x Empty -- Caso trivial 2
-- Caso recursivo, usamos a função auxiliar para
-- "emprestar" elementos da espinha ou de r
viewL (Deep l s r) =
ConsV (dFirst l) (deepL (dTail l) s r)
Reconstruindo a cauda:
-- Recebe o que sobrou de l (que pode ser nada) e
-- devolve uma árvore válida.
-- Empresta da direita caso necessário.
deepL :: Maybe (Digit a) -- Sobra de l
-> FingerTree (Node a) -- Espinha
-> Digit a -- r
-> FingerTree a
-- Se sobrou é trivial, remonta a árvore e devolve
deepL (Just l) s r = Deep l s r
deepL Nothing s r =
case viewL s of
Nil -> digitToTree r
ConsV a s'->
case a of
Node2 x y -> Deep (Two x y) s' r
Node3 x y z -> Deep (Three x y z) s' r
4.7 Implementando viewR
A implementação de viewR é simétrica:
dLast :: Digit a -> a
dLast (One z) = z
dLast (Two _ z) = z
dLast (Three _ _ z) = z
dLast (Four _ _ _ z) = z
dInit :: Digit a -> Maybe (Digit a)
dInit One{} = Nothing
dInit (Two a _) = Just $ One a
dInit (Three a b _) = Just $ Two a b
dInit (Four a b c _) = Just $ Three a b
viewR :: FingerTree a -> View FingerTree a
viewR Empty = Nil
viewR (Single x) = ConsV x Empty
viewR (Deep l s r) =
ConsV (dLast r) (deepR l s (dInit r))
Reconstruindo o prefixo:
deepR :: Digit a
-> FingerTree (Node a)
-> Maybe (Digit a)
-> FingerTree a
deepR l s (Just r) = Deep l s r
deepR l s Nothing =
case viewR s of
Nil -> digitToTree l
ConsV a s'->
case a of
Node2 x y -> Deep l s' (Two x y)
Node3 x y z -> Deep l s' (Three x y z)
4.8 Comentários sobre a eficiência de views
head t =
case viewL t of
ConsV x _ -> x
Nil ->
error "head: empty"
tail t =
case viewL t of
ConsV _ xs -> xs
Nil ->
error "tail: empty"
A implementação acima é apropriado apenas para linguagens com avaliação preguiçosa.
- Em outras linguagens, pode ser interessante criar funções
específicas para
headetail(lasteinit) além das funçõesviewL/R.
Novamente, as operações podem levar \(O(\lg n)\) no pior caso. Contudo é possível mostrar que o seu custo amortizado é \(O(1)\).
-
A chave para fazer a análise é classificar o estado dos
Digit(eNode) em seguros ou inseguros.- Aqueles com 2 ou 3 elementos são seguros e aqueles com 1 ou 4 inseguros.
-
Uma operação no deque propaga apenas se o valor em questão for inseguro.
-
Mas após a operação o valor se torna seguro novamente!
-
Isso garante que no máximo \(\frac{1}{2}\) das operações precisa descer ao próximo nível, \(\frac{1}{4}\) ao nível seguinte, …
-
Logo, o custo amortizado é constante.
Para entender como isso ocorre, simule manualmente uma sequência de
operações até ocorrer uma propagação.
Em seguida faça a operação oposta (cons/tail, snoc/init) à
operação que desencadeou a propagação.
A árvore volta ao estado anterior? Em outras palavras, tail (cons x t) é exatamente igual à t?
4.9 Uma instância de Foldable
Podemos definir uma instância de Foldable para nossa árvore
-- Folding para Digit
instance Foldable Digit where
foldMap f (One a) = f a
foldMap f (Two a b) = f a <> f b
foldMap f (Three a b c) = f a <> f b <> f c
foldMap f (Four a b c d) = f a <> f b <> f c <> f d
instance Foldable (Node v) where
foldMap f (Node2 _ a b) = f a <> f b
foldMap f (Node3 _ a b c) = f a <> f b <> f c
-- -- Elementos da esquerda para a direita
instance Foldable (FingerTree v) where
foldMap _ Empty = mempty
foldMap f (Single x) = f x
foldMap f (Deep _ l s r) =
foldMap f l <> foldMap (foldMap f) s <> foldMap f r
E com isso podemos transformar facilmente uma finger tree em uma lista, por exemplo:
import qualified Data.Foldable as F
...
-- Transforma uma FingerTree (foldable) em uma lista
print . F.toList $ treeFromList [1,5,2,9,0,10,4,6,7]
print . F.toList $ hinzePatterson |> '!'
4.10 Experimente no Repl.it
Experimente o código dessa seção no Repl.it abaixo:
5 Referências
Este material foi fortemente baseado nas seguintes fontes:
-
“Finger Trees: A Simple General-purpose Data Structure”, por Ralf Hinze and Ross Paterson, Journal of Functional Programming 16(2):197–217, 2006.
-
“Finger Trees”, por Andrew Gibiansky
-
“Monoids and Finger Trees”, por Heinrich Apfelmus
5.1 Código
- O código fonte completo dos slides pode ser baixado aqui. Este repositório também contém alguns exercícios.
- A versão otimizada e “oficial” que guarda bastante semelhança ao código didático pode ser vista aqui.
5.2 Livros

- [CO]
- Purely Functional Data Structures
- Por Chris Okasaki
6 Disclaimer
Estes slides foram preparados para os cursos de Paradigmas de Programação e Desenvolvimento Orientado a Tipos na UFABC.
Este material pode ser usado livremente desde que sejam mantidos, além deste aviso, os créditos aos autores e instituições.
